
Category: Virtual Reseach Environments
-
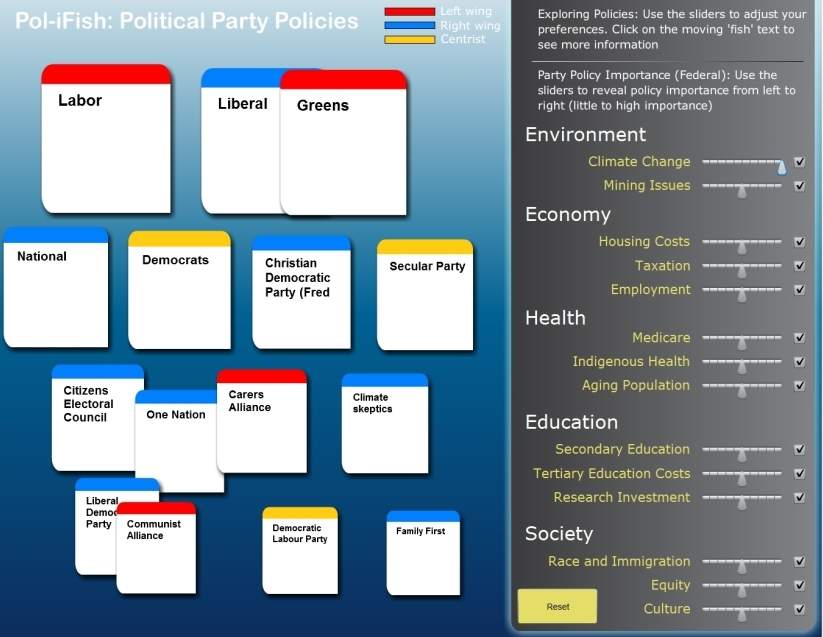
Political Issue Analysis System
The report from the project is available (here). And have fun with the prototype (click on the image below). The Internet is recognised as a vital component of our political information systems. Although extensively used by governments and civil society groups, its effects on political processes, particularly deliberative political processes, remain relatively unknown. Emerging research…
-
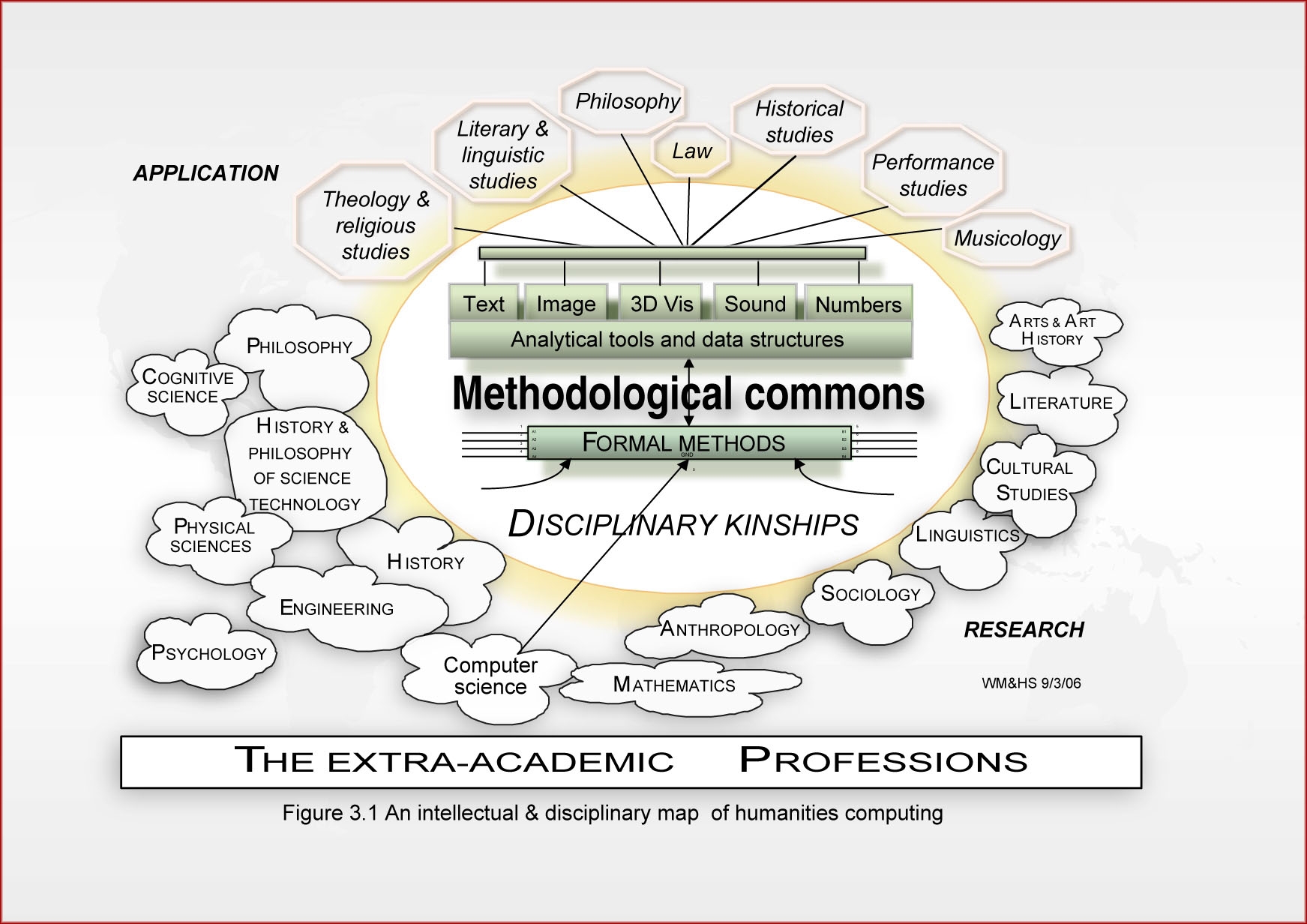
Data versus method (data needs heads!)
I have been thinking a little more about the relationship between eResearch and Digital Humanities of late, partly because it is the subject of my talk at the Digital Humanities conference in Hamburg in July, and I want to do justice to what I see as a critical topic that hasn’t been mainly well handled…
-
Open Science and Data
As part of JISC’s ‘Research 3.0 – driving the knowledge economy’ activity which launches at the end of November, a new Open Science report released today trails key research trends that could have far-reaching implications for science, universities and UK society. The report written by UKOLN at the University of Bath and the Digital Curation…
-
Report back: ‘Tools for Scholarly Editing over the Web’ Birmingham, 24 September
I attended the ‘Tools for Scholarly Editing over the Web’ workshop on Thursday (24 September) organised by the Institute for Textual Scholarship and Electronic Editing at the University of Birmingham. There were presentation by many leading figures of electronic textual editing from the US, Canada, Germany, Italy, Australia, Ireland, and Britain. The workshop was organised…
-
‘Tools for Collaborative Scholarly Editing over the Web’
University of Birmingham,24-25 September, 2009. This workshop will review and address the making of tools for collaborative scholarly editing over the web. The workshop leaders joins partners in the COST-ESF Interedition project (http://www.interedition.eu), which is focussing – as is the JISC-funded Virtual Manuscript Room project — on Europe-wide creation of infrastructure and tools for collaborative…
-
NINES Project: Ninteenth Century Scholarship Online (Peer Review system)
The Peer review system for the NINES project may be of interest to punters. Digital humanities projects have long lacked a framework for peer review and thus have often had difficulty establishing their credibility as true scholarship. NINES exists in part to address this situation by instituting a robust system of review by some of…